📌 この記事はこんな人向けです
- 🔧 QAエンジニア → リンク切れ検出を自動化してテスト工数を削減したい人
- 🔍 SEO担当者 → リンク切れを放置してSEO評価が下がるのを防ぎたい人
- ⚙️ テスト自動化エンジニア → SeleniumとPythonで実務レベルのツールを作りたい人
🔥 この記事を読むと得られること
- SEOに悪影響を与える「リンク切れ」を自動で検出できる
- 手動チェックが完全に不要になる
- 404だけでなく4xx/5xx全ステータスに対応したチェックが実装できる
- QA・テスト自動化・SEO対策の3つ全部に使える実務レベルのコードが手に入る
Webサイトの運用で地味に困るのがリンク切れ(404エラー)の存在です。手動でチェックするのは時間がかかりすぎる、でも放置するとSEO評価や信頼性にも影響する——そんな悩みを解決するために作ったQA自動化ツールが LinkChecker です。
この記事では Selenium × Python で実装したリンクチェッカーのコードを、設計の意図・各メソッドの役割・ハマりポイントまで含めて徹底解説します。実行結果のサンプルやCSV出力例も掲載しているので、すぐに動かしてみてください。
- 00. リンク切れがSEOに与える影響
- 01. 実行結果サンプル(動くか一目で確認)
- 02. なぜ Selenium + requests の組み合わせなのか?
- 01. 対応しているエラーステータス一覧
- 02. 環境構築と必要なライブラリ
- 03. クラス構造と責務の設計
- 04. __init__ と初期設定
- 05. get_all_links — リンクの収集戦略
- 06. check_link_status — 二段階ステータス確認
- 07. take_screenshot — エビデンス収集
- 08. handle_cookie_popup — GDPR 対応
- 09. save_results — CSV レポート出力
- 10. よくあるエラーと対処法
- 11. 大量URLをチェックする場合の高速化
- 12. さらに良くするための改善アイデア
- 13. ハマりポイント
- 14. まとめ
00. リンク切れがSEOに与える影響
「リンク切れはユーザーが困るだけ」と思われがちですが、実はSEOへの影響も深刻です。壊れたリンクはサイトの品質・検索評価・ユーザー体験の全てに悪影響を与えます。
Googlebot がリンク切れに遭遇するとクロールバジェットを無駄消費し他のページが巡回されにくくなる
404ページが多いサイトはGoogleから「品質が低い」と判断されSEO評価が下がる可能性がある
リンク切れに遭遇したユーザーはすぐ離脱。直帰率の上昇が間接的にSEOにも悪影響を与える
01. 実行結果サンプル(動くか一目で確認)
実際に動かすと、URL・ステータス・結果が一覧で出力されます。リンク切れをパッと見で判断できる形式です。
| URL | ステータス | 結果 |
|---|---|---|
| https://example.com | 200 | ✅ OK |
| https://example.com/about | 200 | ✅ OK |
| https://example.com/recruit | 404 | ❌ Not Found |
| https://example.com/old-page | 410 | ❌ Gone |
| https://example.com/contact | 200 | ✅ OK |
ターミナルにも同様の形式でリアルタイム出力されます。
=== 実行結果例 ===
[チェック中] /top → 200 OK
[チェック中] /about → 200 OK
[チェック中] /404 → 404 Not Found ← リンク切れ検出!
[チェック中] /old → 410 Gone ← 削除済みページ検出!
=== サマリー ===
総リンク数: 89 / エラーリンク数: 3
📸 スクリーンショット保存済み
📊 CSV出力済み → Desktop/LinkChecker/
実際に筆者の環境で動かした結果がこちらです。総リンク数128件中、エラーリンク2件を検出し、CSVとスクリーンショットが自動保存されました。
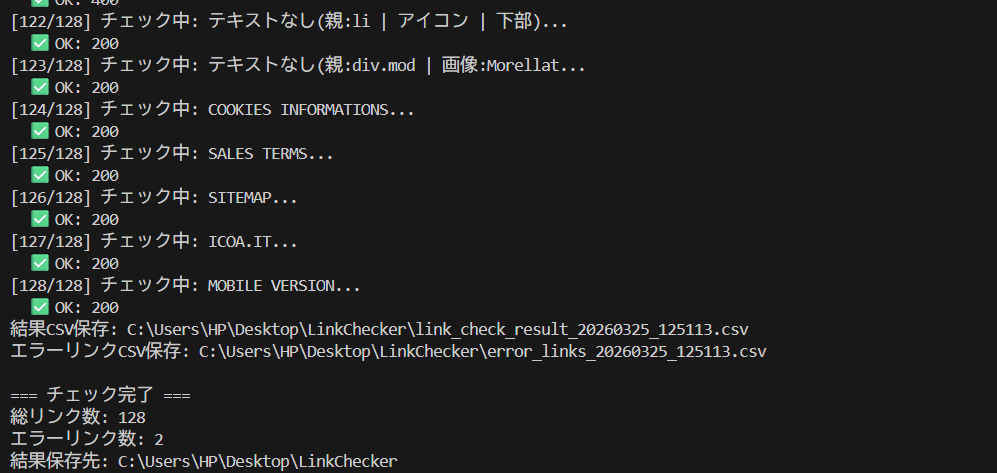
▲ 実際のターミナル出力。128件チェックし2件のエラーリンクを検出。CSVとSSが自動保存される
エラー検出時は以下のようにエラーページのスクリーンショットが自動保存されます。

▲ 404エラー検出時に自動保存されるスクリーンショット
自動生成されるCSVレポート(保存して使える)
実務では「結果を残すこと」が必須です。このツールはチェック完了後にCSVを自動生成するので、バグチケットへの添付・SEO担当者への共有・修正作業の優先度付けにそのまま使えます。
リンクテキスト,URL,ステータスコード,キャプチャパス,チェック時刻
トップページ,https://example.com,200,,2026-03-19 14:30:01
会社概要,https://example.com/about,200,,2026-03-19 14:30:03
採用情報,https://example.com/recruit,404,screenshots/404_採用情報.png,2026-03-19 14:30:22
旧ページ,https://example.com/old-page,410,screenshots/410_旧ページ.png,2026-03-19 14:30:24
お問い合わせ,https://example.com/contact,200,,2026-03-19 14:30:25実際に生成されたCSVをExcelで開くとこのように表示されます。リンクテキスト・URL・ステータスコード・スクリーンショットのパスが一覧で確認でき、そのままバグチケットに添付できます。

▲ 自動生成されたCSVをExcelで開いた様子。エラーリンクのURL・ステータス・SSパスが整理されている
全リンクの結果を一覧で保存。統計・分析に活用できる
エラーのみ抽出して別ファイルで保存。修正作業がすぐ始められる
02. なぜ Selenium + requests の組み合わせなのか?
「Seleniumだけでいいのでは?」と思う方も多いかもしれません。実はこれ、Selenium単体ではHTTPステータスコードを直接取得できないという問題があります。
💡 実務での正解はこれ
Seleniumはリンク抽出・DOM操作、ステータス確認はrequestsを使うのが実務的な分担です。この使い分けができているだけで「分かっているエンジニア」の印象になります。
| ツール | 得意なこと | 苦手なこと |
|---|---|---|
| Selenium | DOM操作・JS実行・Cookie処理・ページ描画 | HTTPステータスコードの直接取得 |
| requests | HTTPステータスの高速チェック・軽量 | JS認証・Cookie処理・動的コンテンツ |
01. 対応しているエラーステータス一覧
「リンク切れ = 404」と思われがちですが、実務では4xx/5xx全体を対象にするのが一般的です。このツールは以下のステータスを検出します。
| ステータス | 意味 | 対応 |
|---|---|---|
| 404 | ページが存在しない(典型的なリンク切れ) | ✅ 検出・SS撮影 |
| 410 | ページが恒久的に削除された | ✅ 検出・SS撮影 |
| 500 | サーバー内部エラー | ✅ 検出・SS撮影 |
| 502/503/504 | ゲートウェイ・サービス利用不可 | ✅ 検出・SS撮影 |
| 403 | アクセス制限(ページ自体は存在する) | ⏭️ スキップ(正常扱い) |
| 200/301/302 | 正常・リダイレクト | ✅ 正常と判定 |
02. 環境構築と必要なライブラリ
# 必要なライブラリを一括インストール
pip install selenium requestsWindows/Mac両方で動作。クロスプラットフォーム対応
ChromeDriver自動検出に対応。Service()引数なしで起動できる
HTTPステータスの高速チェックに使用。大量リンクに対応
03. クラス構造と責務の設計
# 使い方はたったの3行
checker = LinkChecker("https://example.com")
results = checker.run_check()
checker.close()class LinkChecker:
__init__ # 初期化・出力先・WebDriver起動・エラーリスト初期化
│
├── setup_output_directory # フォルダ作成
├── setup_driver # Chrome オプション設定・ドライバー起動
│
├── run_check # ★ メインループ(全体制御)
│ ├── get_all_links # Selenium でリンク収集
│ ├── check_link_status # HTTP ステータス確認
│ └── take_screenshot # エラーページ SS 撮影
│
├── save_results # CSV 保存
└── close # WebDriver 終了04. __init__ と初期設定
コンストラクタ
def __init__(self, base_url, output_dir=None):
if output_dir is None:
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
output_dir = os.path.join(desktop_path, "LinkChecker")
self.base_url = base_url
self.output_dir = output_dir
self.setup_output_directory()
self.setup_driver()
self.error_links = []setup_driver — Chrome オプション
| カテゴリ | オプション例 | 目的 |
|---|---|---|
| ボット検出回避 | --disable-blink-features=AutomationControlled | 自動操作であることを悟られないようにする |
| ログ完全抑制 | --log-level=3 / --silent | ターミナル出力をツール自身のログのみにする |
| UA偽装 | Windows Chrome の UserAgent を設定 | クローラーブロックを回避 |
| WebDriver隠蔽 | navigator.webdriver を undefined に書き換え | JSレベルのボット検出を無効化 |
05. get_all_links — リンクの収集戦略
- ページアクセス & 初期待機 —
time.sleep(2)で動的コンテンツのロードを待機 - Cookie ポップアップ処理 —
handle_cookie_popup()でGDPR同意ダイアログを自動クリック - 全 a タグを取得 —
find_elements(By.TAG_NAME, "a")でHTTPで始まるURLのみをフィルタリング - 要素情報を事前保存(Stale Element対策) — location/size/XPathなどを dict として保存
- テキストなしリンクの補完 —
title → alt → aria-labelの順にフォールバック取得
Stale Element 対策
# ❌ ダメな例
elements = driver.find_elements(By.TAG_NAME, "a")
do_something()
elements[0].click() # ← StaleElementReferenceException 発生!
# ✅ 良い例:情報を先にdictに退避
element_data = {
'location': element.location,
'classes': element.get_attribute("class") or "",
'id': element.get_attribute("id") or "",
'xpath': self.get_element_xpath(element)
}06. check_link_status — 二段階ステータス確認
| 手法 | メリット | デメリット |
|---|---|---|
requests.head() | ボディ取得なしで高速・軽量 | HEAD を拒否するサーバーがある |
requests.get() | ほぼ全サーバーが対応 | ボディ取得分で低速 |
check_with_selenium() | JS認証・リダイレクトも正確に判定 | 最も低速 |
# まず HEAD リクエストで軽量チェック
response = requests.head(url, timeout=8, allow_redirects=True, headers=headers)
status_code = response.status_code
# 400番台(403/404以外)はGETで再確認
if 400 <= status_code < 500 and status_code not in [403, 404]:
response = requests.get(url, timeout=8, allow_redirects=True, headers=headers)
return response.status_code07. take_screenshot — エビデンス収集
404/500等のエラーページをキャプチャ。404_テキスト_タイムスタンプ.png で保存
元ページに戻り問題リンクを赤枠ハイライト+「ERROR LINK」バナーをJS注入してキャプチャ
# 要素に赤枠・グローエフェクトを適用
element.style.cssText += `
border: 3px solid #ff0000 !important;
box-shadow: 0 0 15px rgba(255, 0, 0, 0.8) !important;
`;
# 画面上部に固定バナーを追加
var label = document.createElement('div');
label.innerHTML = 'ERROR LINK: ' + linkText.substring(0, 30);
label.style.cssText = `
position: fixed; top: 20px; left: 50%;
background: #ff0000; color: white; padding: 10px 20px;
`;実際に生成されるBEFOREスクリーンショットがこちらです。問題のあるリンクが赤枠でハイライトされ、上部に「ERROR LINK」バナーが自動挿入されるため、どのリンクが原因かが一目でわかります。
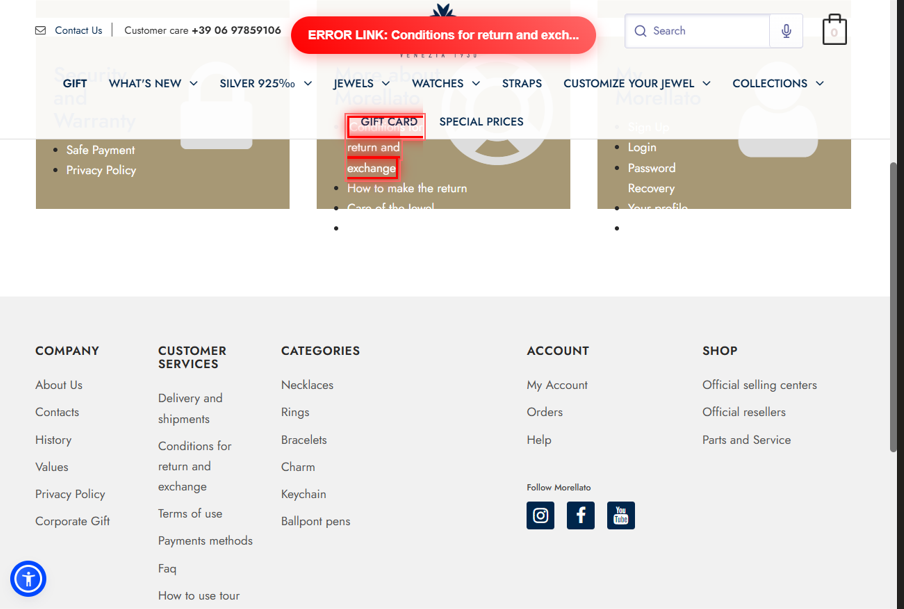
▲ エラーリンクを赤枠でハイライト+「ERROR LINK」バナーをJS注入してキャプチャ。証拠として残せる
08. handle_cookie_popup — GDPR 対応
cookie_selectors = [
"//button[contains(text(), 'Accetta tutti i cookie')]", # イタリア語
"//button[contains(text(), 'Accept')]", # 英語
"//button[contains(text(), '同意')]", # 日本語
"//button[contains(@class, 'accept')]", # クラスベース
]
self.driver.execute_script("arguments[0].click();", button)09. save_results — CSV レポート出力
| ファイル | 内容 | 用途 |
|---|---|---|
link_check_result_*.csv | 全リンクのチェック結果 | 全体確認・統計 |
error_links_*.csv | エラーのあったリンクのみ | バグレポート添付・修正作業 |
# utf-8-sig = BOM付きUTF-8(Excelで文字化けを防止)
with open(csv_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
error_count = sum(1 for r in results if r['ステータスコード'] in [404, 410, 500, 502, 503])
print(f"✅ 正常リンク : {len(results) - error_count}件")
print(f"❌ エラーリンク: {error_count}件")10. よくあるエラーと対処法
① ChromeDriver のバージョン不一致
# 対処法:selenium 4.6+ にアップグレードで自動解決
pip install --upgrade selenium② TimeoutException — ページが読み込めない
self.driver.set_page_load_timeout(30) # 15秒 → 30秒に延長③ aタグが0件しか取得できない
time.sleep(5) # 2秒 → 5秒に増やして再試行11. 大量URLをチェックする場合の高速化
現状のツールは1件ずつ順番にチェックするため、100件を超えてくると処理時間が長くなります。
① concurrent.futures で並列処理
from concurrent.futures import ThreadPoolExecutor, as_completed
def check_links_parallel(links, max_workers=10):
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_link = {
executor.submit(check_link_status, link['url']): link
for link in links
}
for future in as_completed(future_to_link):
link = future_to_link[future]
status = future.result()
results.append({'url': link['url'], 'status': status})
return results② タイムアウト設定とリトライ処理
def check_with_retry(url, max_retries=3, timeout=8):
for attempt in range(max_retries):
try:
response = requests.head(url, timeout=timeout, allow_redirects=True)
return response.status_code
except requests.exceptions.Timeout:
if attempt < max_retries - 1:
time.sleep(2)
return 012. さらに良くするための改善アイデア
concurrent.futures で並列実行。1000件のリンクを高速チェック可能に
内部リンクを再帰的にたどることでサイト全体を一括チェック可能に
タイムアウト時に自動リトライ。一時的なサーバーエラーによる誤検知を防ぐ
mailto: や tel: をスキップリストに追加して不要なチェックを省く
13. ハマりポイント
実装中に実際につまずいた箇所をまとめました。同じところでハマる方の参考になれば嬉しいです。
① Seleniumだけではステータスコードが取れない
「Seleniumだけでリンク切れチェックできるはず!」と思ってコードを書き始めましたが、SeleniumはDOM操作は得意でもHTTPステータスコードを直接取得する機能がありません。
解決策として requests ライブラリと組み合わせる方法にたどり着きました。
# ❌ SeleniumだけではHTTPステータスが取れない
# ✅ requestsと組み合わせて解決
response = requests.head(url, timeout=8, allow_redirects=True)
status_code = response.status_code💡 ポイント: Seleniumとrequestsをそれぞれの得意領域で使い分けることが実務の正解です。
② StaleElementReferenceException が発生する
リンクを取得した後にDOMが更新されると、取得済みの要素が無効になり StaleElementReferenceException が発生します。最初はなぜエラーになるのか全く理解できませんでした。
解決策は要素の情報を事前にdictに保存しておくことです。
# ❌ ダメな例:後から要素を操作しようとするとエラー
elements = driver.find_elements(By.TAG_NAME, "a")
do_something()
elements[0].click() # ← StaleElementReferenceException!
# ✅ 良い例:先にdictに情報を退避
element_data = {
'href': element.get_attribute("href"),
'text': element.text,
}💡 ポイント: 要素参照を後から使うのではなく、必要な情報を取得した直後にdictへ保存する習慣をつけると安定します。
③ aタグが0件しか取得できない
find_elements(By.TAG_NAME, "a") を実行しても0件しか取れないケースが発生しました。原因はJavaScriptで動的に生成されるコンテンツのロード待ちが足りていなかったことでした。
# ❌ 0件になることがある
driver.get(url)
elements = driver.find_elements(By.TAG_NAME, "a")
# ✅ 待機時間を増やして解決
driver.get(url)
time.sleep(5) # 2秒 → 5秒に増やす
elements = driver.find_elements(By.TAG_NAME, "a")⚠️ 注意: time.sleep() の値はサイトの読み込み速度によって調整が必要です。重いサイトでは10秒以上必要なケースもあります。
④ HEADリクエストを拒否するサーバーがある
requests.head() で軽量チェックをしようとしたところ、サーバーによってはHEADメソッドを拒否して405エラーを返すことがありました。
解決策はHEADが失敗したらGETで再確認する二段階チェックにすることです。
# まずHEADで軽量チェック
response = requests.head(url, timeout=8)
# 400番台が返ってきたらGETで再確認
if 400 <= response.status_code < 500:
response = requests.get(url, timeout=8)💡 ポイント: HEAD → GET のフォールバック構成にすることで、サーバーの違いによる誤検知を防げます。
⑤ ChromeDriverのバージョン不一致
Chromeをアップデートした後にスクリプトを実行したら突然動かなくなりました。原因はChromeとChromeDriverのバージョンが合わなくなったことでした。
# ✅ seleniumを4.6以上にアップグレードで自動解決
pip install --upgrade selenium💡 ポイント: Selenium 4.6以降はChromeDriverを自動で管理してくれるので、この問題が根本解決されます。バージョン管理の手間がなくなるため、まず最新版にアップグレードすることをおすすめします。
14. まとめ
スクリプトを実行すると、screenshotsフォルダにエラーページSS(404_)とエラー前SS(BEFORE_)がセットで自動保存されます。ファイル名にリンクテキストとタイムスタンプが入るので、後から見返す際も迷いません。
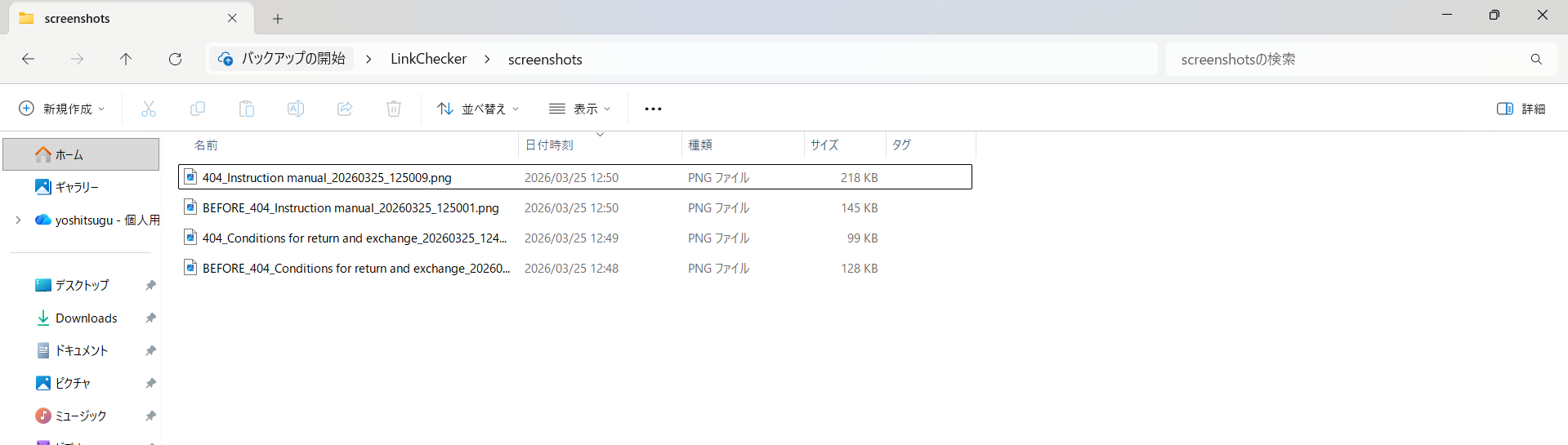
▲ 自動保存されるscreenshotsフォルダの中身。エラーページSS(404_)とエラー前SS(BEFORE_)がセットで保存される
- Seleniumはリンク抽出・DOM操作、requestsはステータス確認という役割分担が実務の正解
- 404だけでなく 4xx/5xx全体 を対象にするのが実務的なアプローチ
- エビデンスとしてエラー前後のスクリーンショットを自動生成できる
- 結果はExcel対応CSVで自動出力されるのでバグチケットにそのまま添付できる
- SEO改善 → リンク切れを定期監視して検索評価の低下を防げる
- CI/CDに組み込む → リリース前に自動でリンクチェックが走る品質ゲートが作れる
- 定期監視 → cronやタスクスケジューラと組み合わせて週次・月次で自動実行できる
このツールの活用シーンと拡張例
リンク切れはGoogleの評価を下げる要因。週次・月次で定期実行し常に健全なサイトを維持できる
リリース前のリンク品質チェックをテストスイートに組み込み。エビデンスのSSも自動生成される
GitHub ActionsやJenkinsに組み込めばリリース前に自動でリンクチェックが走る品質ゲートが作れる
cronやWindowsタスクスケジューラと組み合わせて週次・月次で自動実行。問題を早期発見できる
🚀 今後の拡張例
- 全ページクロール対応 → 内部リンクを再帰的にたどり、サイト全体を一括チェック
- 並列処理(concurrent.futures) → 1000件のURLを高速処理
- 定期実行 + Slack通知 → cronで自動実行し、エラー検出時にSlackへ即時通知