📌 이런 분들을 위한 글입니다
- 🔧 QA 엔지니어 → 깨진 링크 탐지를 자동화해서 테스트 공수를 줄이고 싶은 분
- 🔍 SEO 담당자 → 깨진 링크 방치로 인한 SEO 점수 하락을 막고 싶은 분
- ⚙️ 테스트 자동화 엔지니어 → Selenium과 Python으로 실무 수준의 도구를 만들고 싶은 분
🔥 이 글을 읽으면 얻을 수 있는 것
- SEO에 악영향을 주는 「깨진 링크」를 자동으로 탐지할 수 있다
- 수동 링크 확인 작업이 완전히 필요 없어진다
- 404뿐만 아니라 4xx/5xx 전체 상태 코드에 대응한 검사를 구현할 수 있다
- QA·테스트 자동화·SEO 대책 3가지 모두에 활용 가능한 실무 수준의 코드를 얻을 수 있다
웹사이트 운영에서 은근히 골치 아픈 문제가 바로 깨진 링크(404 에러)의 존재입니다. 수동으로 확인하기엔 시간이 너무 오래 걸리고, 그렇다고 방치하면 SEO 평가와 신뢰성에도 영향을 미칩니다. 그 고민을 해결하기 위해 만든 QA 자동화 도구가 바로 LinkChecker입니다.
이 글에서는 Selenium × Python으로 구현한 링크 체커의 코드를, 설계 의도·각 메서드의 역할·자주 발생하는 문제까지 포함해 철저하게 해설합니다. 실행 결과 샘플과 CSV 출력 예시도 포함되어 있으니 바로 실행해 보세요.
- 00. 깨진 링크가 SEO에 미치는 영향
- 01. 실행 결과 샘플(먼저 동작 확인!)
- 02. 왜 Selenium + requests 조합인가?
- 03. 대응하는 에러 상태 코드 일람
- 04. 환경 구축과 필요한 라이브러리
- 05. 클래스 구조와 설계
- 06. __init__ 와 초기 설정
- 07. get_all_links — 링크 수집 전략
- 08. check_link_status — 2단계 상태 코드 확인
- 09. take_screenshot — 증거 수집
- 10. handle_cookie_popup — GDPR 대응
- 11. save_results — CSV 리포트 출력
- 12. 자주 발생하는 에러와 대처법
- 13. 대량 URL을 확인할 때의 고속화
- 14. 더 발전시키기 위한 개선 아이디어
- 15. 자주 겪는 문제 & 해결법
- 16. 정리
00. 깨진 링크가 SEO에 미치는 영향
「깨진 링크는 사용자만 불편한 것」이라고 생각하기 쉽지만, 실은 SEO에 미치는 영향도 심각합니다. 깨진 링크는 사이트의 품질·검색 평가·사용자 경험 모두에 악영향을 줍니다.
Googlebot이 깨진 링크를 만나면 크롤 버짓을 낭비해 다른 페이지가 순회되기 어려워집니다
404 페이지가 많은 사이트는 Google로부터 「품질이 낮다」고 판단되어 SEO 평가가 낮아질 수 있습니다
깨진 링크를 만난 사용자는 바로 이탈합니다. 이탈률 상승이 간접적으로 SEO에도 악영향을 줍니다
01. 실행 결과 샘플(먼저 동작 확인!)
실제로 실행하면 URL·상태 코드·결과가 목록으로 출력됩니다. 깨진 링크를 한눈에 파악할 수 있는 형식입니다.
| URL | 상태 코드 | 결과 |
|---|---|---|
| /top | 200 | ✅ 정상 |
| /about | 200 | ✅ 정상 |
| /careers | 404 | ❌ 링크 끊김 |
| /old-page | 410 | ❌ 삭제된 페이지 |
| /contact | 200 | ✅ 정상 |
터미널에도 같은 형식으로 실시간 출력됩니다.
=== 실행 결과 예시 ===
[확인 중] /top → 200 OK
[확인 중] /about → 200 OK
[확인 중] /careers → 404 Not Found ← 링크 끊김 감지!
[확인 중] /old-page → 410 Gone ← 삭제된 페이지 감지!
=== 요약 ===
총 링크 수: 89 / 에러 링크 수: 3
📸 스크린샷 저장 완료
📊 CSV 출력 완료 → Desktop/LinkChecker/
실제로 필자의 환경에서 실행한 결과입니다. 총 128개 링크 중 에러 링크 2개를 감지하고, CSV와 스크린샷이 자동으로 저장되었습니다.
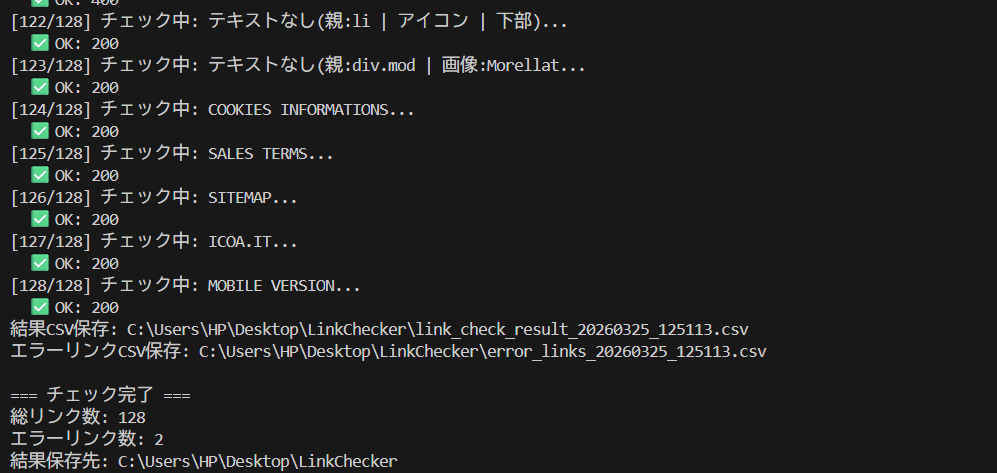
▲ 실제 터미널 출력. 128건 확인 중 2건의 에러 링크를 감지. CSV와 스크린샷이 자동 저장됨
에러 감지 시 다음과 같이 에러 페이지의 스크린샷이 자동으로 저장됩니다.

▲ 404 에러 감지 시 자동 저장되는 스크린샷
자동 생성되는 CSV 리포트(저장해서 재활용)
실무에서는 「결과를 남기는 것」이 필수입니다. 이 도구는 확인 완료 후 CSV를 자동 생성하므로, 버그 티켓 첨부·SEO 담당자와의 공유·수정 작업의 우선순위 결정에 바로 활용할 수 있습니다.
링크 텍스트,URL,상태 코드,스크린샷 경로,확인 시각
상단 페이지,/top,200,,2026-03-19 14:30:01
회사 소개,/about,200,,2026-03-19 14:30:03
채용 정보,/careers,404,screenshots/404_careers.png,2026-03-19 14:30:22
구 페이지,/old-page,410,screenshots/410_old-page.png,2026-03-19 14:30:24
문의하기,/contact,200,,2026-03-19 14:30:25자동 생성된 CSV를 Excel로 열면 이렇게 표시됩니다. 링크 텍스트·URL·상태 코드·스크린샷 경로가 한눈에 정리되어 있어 그대로 버그 티켓에 첨부할 수 있습니다.

▲ 자동 생성된 CSV를 Excel로 열기. 링크 텍스트·URL·상태 코드·스크린샷 경로가 모두 정리되어 있음
모든 링크 확인 결과를 저장. 통계·분석에 활용 가능
에러만 추출해 별도 파일로 저장. 수정 작업을 바로 시작할 수 있음
02. 왜 Selenium + requests 조합인가?
「Selenium만으로도 되지 않나?」라고 생각하는 분도 많을 텐데요. 사실 Selenium 단독으로는 HTTP 상태 코드를 직접 가져올 수 없다는 문제가 있습니다.
💡 실무에서의 정답
Selenium은 링크 추출·DOM 조작을 담당하고, 상태 코드 확인은 requests가 담당하는 것이 실무적인 역할 분담입니다.
| 도구 | 잘하는 것 | 못하는 것 |
|---|---|---|
| Selenium | DOM 조작·JS 실행·Cookie 처리·페이지 렌더링 | HTTP 상태 코드 직접 취득 |
| requests | HTTP 상태 코드 고속 확인·경량 | JS 인증·Cookie 처리·동적 콘텐츠 |
03. 대응하는 에러 상태 코드 일람
| 상태 코드 | 의미 | 대응 |
|---|---|---|
| 404 | 페이지가 존재하지 않음 | ✅ 감지·스크린샷 |
| 410 | 페이지가 영구적으로 삭제됨 | ✅ 감지·스크린샷 |
| 500 | 서버 내부 에러 | ✅ 감지·스크린샷 |
| 502/503/504 | 게이트웨이·서비스 이용 불가 | ✅ 감지·스크린샷 |
| 403 | 접근 제한(페이지 자체는 존재) | ⏭️ 스킵(정상으로 처리) |
| 200/301/302 | 정상·리다이렉트 | ✅ 정상으로 판정 |
04. 환경 구축과 필요한 라이브러리
# 필요한 라이브러리 일괄 설치
pip install selenium requests동작 확인 완료. Windows/Mac 크로스 플랫폼 대응
ChromeDriver 자동 감지 대응. 수동 관리 불필요
HTTP 상태 코드 고속 확인에 사용. 대량 링크 처리에 대응
05. 클래스 구조와 설계
# 사용 방법은 단 3줄
checker = LinkChecker("https://example.com")
results = checker.run_check()
checker.close()class LinkChecker:
__init__ # 초기화·출력 경로·WebDriver 실행·에러 목록 초기화
│
├── setup_output_directory # 폴더 생성
├── setup_driver # Chrome 옵션 설정·드라이버 실행
│
├── run_check # ★ 메인 루프(전체 제어)
│ ├── get_all_links # Selenium으로 링크 수집
│ ├── check_link_status # HTTP 상태 확인
│ └── take_screenshot # 에러 페이지 스크린샷 촬영
│
├── save_results # CSV 저장
└── close # WebDriver 종료06. __init__ 와 초기 설정
def __init__(self, base_url, output_dir=None):
if output_dir is None:
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
output_dir = os.path.join(desktop_path, "LinkChecker")
self.base_url = base_url
self.output_dir = output_dir
self.setup_output_directory()
self.setup_driver()
self.error_links = []07. get_all_links — 링크 수집 전략
- 페이지 접속 & 초기 대기 —
time.sleep(2)로 동적 콘텐츠 로딩을 기다림 - Cookie 팝업 처리 —
handle_cookie_popup()으로 GDPR 동의 다이얼로그를 자동 클릭 - 전체 a 태그 취득 —
find_elements(By.TAG_NAME, "a")로 HTTP로 시작하는 URL만 필터링 - 요소 정보 사전 저장(Stale Element 대책) — location/size/XPath 등을 dict에 저장
- 텍스트 없는 링크 보완 —
title → alt → aria-label순으로 폴백 취득
# ❌ 나쁜 예:DOM이 변경되면 예외 발생
elements = driver.find_elements(By.TAG_NAME, "a")
do_something()
elements[0].click() # ← StaleElementReferenceException!
# ✅ 좋은 예:필요한 정보를 먼저 dict에 모두 저장
element_data = {
'location': element.location,
'classes': element.get_attribute("class") or "",
'id': element.get_attribute("id") or "",
'xpath': self.get_element_xpath(element)
}08. check_link_status — 2단계 상태 코드 확인
# 먼저 HEAD 요청으로 경량 확인
response = requests.head(url, timeout=8, allow_redirects=True, headers=headers)
status_code = response.status_code
# 400번대(403/404 제외)는 GET으로 재확인
if 400 <= status_code < 500 and status_code not in [403, 404]:
response = requests.get(url, timeout=8, allow_redirects=True, headers=headers)
return response.status_code09. take_screenshot — 증거 수집
404/500 등 에러 페이지를 캡처. 404_텍스트_타임스탬프.png로 저장
원래 페이지로 돌아가 문제 링크에 빨간 테두리 하이라이트+「ERROR LINK」배너를 JS로 주입해 캡처
# 요소에 빨간 테두리·글로우 이펙트 적용
element.style.cssText += `
border: 3px solid #ff0000 !important;
box-shadow: 0 0 15px rgba(255, 0, 0, 0.8) !important;
z-index: 999999 !important;
`;
# 화면 상단에 고정 배너 추가
var label = document.createElement('div');
label.innerHTML = 'ERROR LINK: ' + linkText.substring(0, 30);
label.style.cssText = `
position: fixed; top: 20px; left: 50%;
background: #ff0000; color: white; padding: 10px 20px;
`;실제로 생성되는 BEFORE 스크린샷입니다. 문제 링크가 빨간 테두리로 하이라이트되고 「ERROR LINK」 배너가 화면 상단에 자동 주입되어 어느 링크가 원인인지 한눈에 알 수 있습니다.
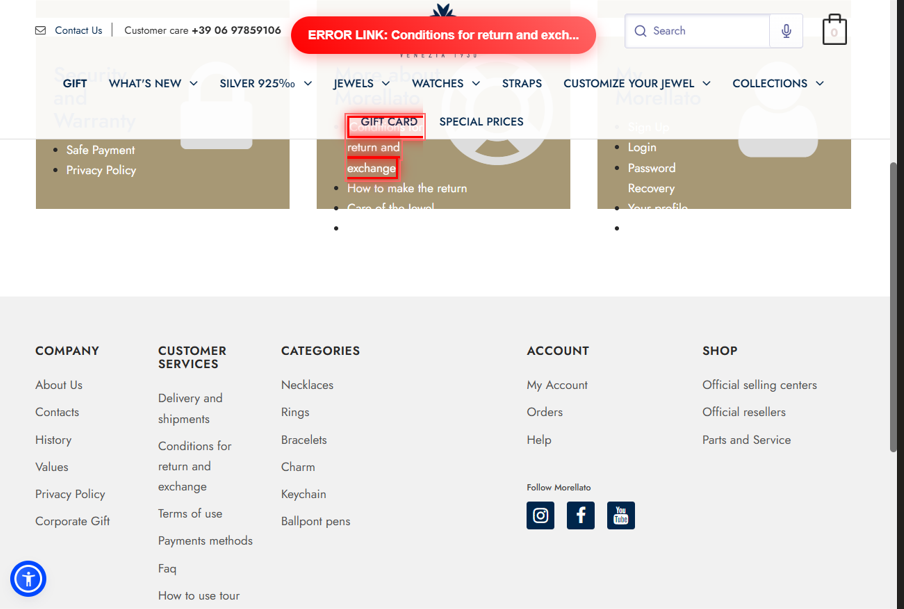
▲ 에러 링크를 빨간 테두리로 하이라이트+「ERROR LINK」배너를 JS로 주입해 캡처. 어느 링크가 문제인지 한눈에 파악 가능
10. handle_cookie_popup — GDPR 대응
cookie_selectors = [
"//button[contains(text(), 'Accept all cookies')]",
"//button[contains(text(), 'Accept')]",
"//button[contains(text(), 'Accetta')]",
"//button[contains(@class, 'accept')]",
]
self.driver.execute_script("arguments[0].click();", button)11. save_results — CSV 리포트 출력
# utf-8-sig = BOM 포함 UTF-8(Excel에서 깨짐 방지)
with open(csv_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
error_count = sum(1 for r in results if r['상태 코드'] in [404, 410, 500, 502, 503])
print(f"✅ 정상 링크 : {len(results) - error_count}건")
print(f"❌ 에러 링크: {error_count}건")12. 자주 발생하는 에러와 대처법
① ChromeDriver 버전 불일치
pip install --upgrade selenium② TimeoutException — 페이지가 로딩되지 않음
self.driver.set_page_load_timeout(30) # 15초 → 30초로 연장③ a 태그가 0건밖에 취득되지 않음
time.sleep(5) # 2초 → 5초로 늘려서 재시도13. 대량 URL을 확인할 때의 고속화
① concurrent.futures로 병렬 처리
from concurrent.futures import ThreadPoolExecutor, as_completed
def check_links_parallel(links, max_workers=10):
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_link = {
executor.submit(check_link_status, link['url']): link
for link in links
}
for future in as_completed(future_to_link):
link = future_to_link[future]
status = future.result()
results.append({'url': link['url'], 'status': status})
return results② 타임아웃 설정과 재시도 처리
def check_with_retry(url, max_retries=3, timeout=8):
for attempt in range(max_retries):
try:
response = requests.head(url, timeout=timeout, allow_redirects=True)
return response.status_code
except requests.exceptions.Timeout:
if attempt < max_retries - 1:
time.sleep(2)
return 014. 더 발전시키기 위한 개선 아이디어
concurrent.futures로 병렬 실행. 1000건 링크를 고속 확인 가능
내부 링크를 재귀적으로 따라가 사이트 전체를 일괄 확인 가능하게
타임아웃 시 자동 재시도로 오검출을 방지
mailto:나 tel:을 스킵 목록에 추가해 불필요한 확인을 생략
15. 자주 겪는 문제 & 해결법
구현 중 실제로 겪었던 문제들을 정리했습니다. 같은 곳에서 막히는 분들께 도움이 되면 좋겠습니다.
① Selenium만으로는 HTTP 상태 코드를 가져올 수 없다
처음에 "Selenium만으로 링크 오류 검출이 가능하겠지!"라고 생각하고 코드를 작성하기 시작했습니다. 하지만 Selenium은 DOM 조작에는 능숙하지만, HTTP 상태 코드를 직접 가져오는 기능이 없습니다.
해결책으로 requests 라이브러리와 조합하는 방법을 찾았습니다.
# ❌ Selenium만으로는 HTTP 상태 코드를 가져올 수 없음
# ✅ requests와 조합하여 해결
response = requests.head(url, timeout=8, allow_redirects=True)
status_code = response.status_code💡 포인트: Selenium은 링크 추출·DOM 조작, requests는 상태 코드 확인으로 역할을 분담하는 것이 실무에서의 정답입니다.
② StaleElementReferenceException 발생
링크를 가져온 후 DOM이 업데이트되면, 이미 가져온 요소의 참조가 무효화되어 StaleElementReferenceException 이 발생합니다. 처음에는 왜 오류가 나는지 전혀 이해할 수 없었습니다.
해결책은 요소 정보를 미리 dict에 저장해두는 것입니다.
# ❌ 나쁜 예: 나중에 요소를 조작하려고 하면 오류 발생
elements = driver.find_elements(By.TAG_NAME, "a")
do_something()
elements[0].click() # ← StaleElementReferenceException!
# ✅ 좋은 예: 미리 dict에 정보를 저장
element_data = {
'href': element.get_attribute("href"),
'text': element.text,
}💡 포인트: 요소 참조를 나중에 사용하는 것이 아니라, 필요한 정보를 가져온 직후에 dict에 저장하는 습관을 들이면 안정적으로 동작합니다.
③ a태그가 0건밖에 가져와지지 않는다
find_elements(By.TAG_NAME, "a") 를 실행해도 0건밖에 가져오지 못하는 경우가 발생했습니다. 원인은 JavaScript로 동적으로 생성되는 콘텐츠의 로딩 대기 시간이 부족했던 것이었습니다.
# ❌ 0건이 될 수 있음
driver.get(url)
elements = driver.find_elements(By.TAG_NAME, "a")
# ✅ 대기 시간을 늘려서 해결
driver.get(url)
time.sleep(5) # 2초 → 5초로 늘림
elements = driver.find_elements(By.TAG_NAME, "a")⚠️ 주의: time.sleep() 의 값은 사이트의 로딩 속도에 따라 조정이 필요합니다. 무거운 사이트에서는 10초 이상 필요한 경우도 있습니다.
④ HEAD 요청을 거부하는 서버가 있다
requests.head() 로 가벼운 체크를 시도했더니, 서버에 따라서는 HEAD 메서드를 거부하고 405 오류를 반환하는 경우가 있었습니다.
해결책은 HEAD가 실패하면 GET으로 재확인하는 2단계 체크로 만드는 것입니다.
# 먼저 HEAD로 가벼운 체크
response = requests.head(url, timeout=8)
# 400번대가 반환되면 GET으로 재확인
if 400 <= response.status_code < 500:
response = requests.get(url, timeout=8)💡 포인트: HEAD → GET 폴백 구성으로 서버 차이에 의한 오탐지를 방지할 수 있습니다.
⑤ ChromeDriver 버전 불일치
Chrome을 업데이트한 후 스크립트를 실행하니 갑자기 동작하지 않게 됐습니다. 원인은 Chrome과 ChromeDriver의 버전이 맞지 않게 된 것이었습니다.
# ✅ selenium 4.6 이상으로 업그레이드하면 자동 해결
pip install --upgrade selenium💡 포인트: Selenium 4.6 이상은 ChromeDriver를 자동으로 관리해주기 때문에 이 문제가 근본적으로 해결됩니다. 수동 버전 관리가 필요 없어지므로 먼저 최신 버전으로 업그레이드하는 것을 권장합니다.
16. 정리
스크립트를 실행하면 screenshots 폴더에 에러 페이지 스크린샷(404_)과 에러 전 스크린샷(BEFORE_)이 세트로 자동 저장됩니다. 파일명에 링크 텍스트와 타임스탬프가 포함되어 있어 나중에 찾아보기도 쉽습니다.
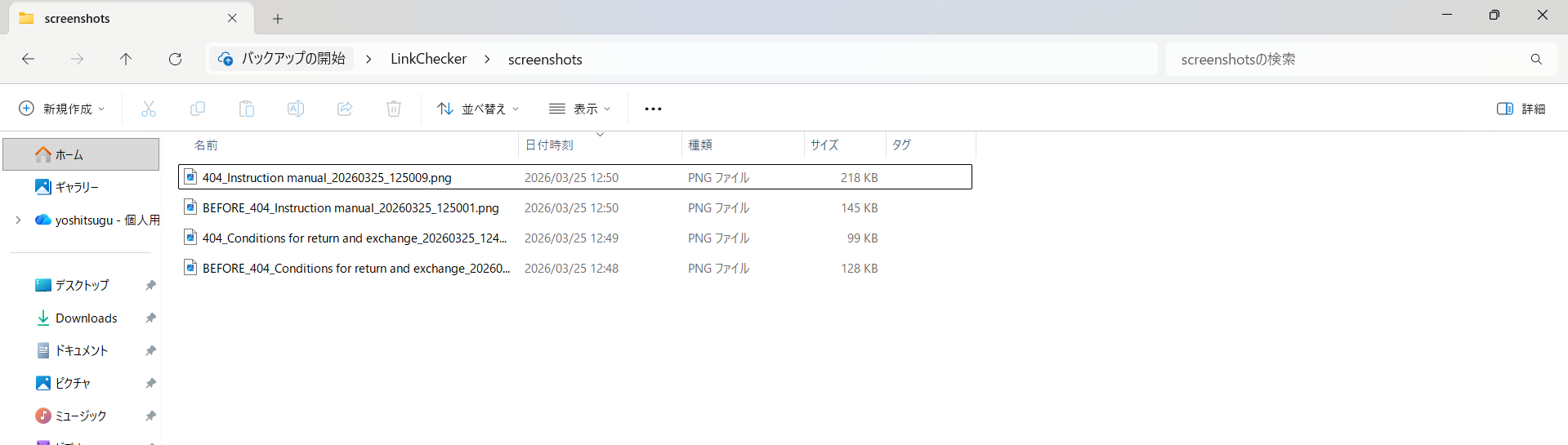
▲ 자동 저장되는 screenshots 폴더 내용. 에러 페이지 스크린샷(404_)과 에러 전 스크린샷(BEFORE_)이 세트로 저장됨
- Selenium은 링크 추출·DOM 조작,requests는 상태 확인이라는 역할 분담이 실무의 정답
- 404뿐만 아니라 4xx/5xx 전체를 대상으로 하는 것이 실무적인 접근
- 증거로서 에러 전후의 스크린샷을 자동 생성 가능
- 결과는 Excel 대응 CSV로 자동 출력되어 버그 티켓에 바로 첨부 가능
- SEO 개선 → 링크 끊김을 정기 감시해 검색 평가 하락을 방지 가능
- CI/CD에 통합 → 릴리스 전에 자동으로 링크 확인이 실행되는 품질 게이트 구축 가능
- 정기 감시 → cron이나 작업 스케줄러와 조합해 주간·월간으로 자동 실행 가능
이 도구의 3가지 활용 장면
링크 끊김은 Google 평가를 낮추는 요인. 주간·월간으로 정기 실행해 항상 건전한 사이트를 유지
릴리스 전 링크 품질 확인을 테스트 스위트에 통합. 증거 스크린샷도 자동 생성됨
GitHub Actions나 Jenkins에 통합하면 매 배포 전에 자동으로 링크 확인이 실행되는 품질 게이트 구축 가능
cron이나 Windows 작업 스케줄러와 조합해 주간·월간으로 자동 실행. 문제를 조기에 발견 가능
🚀 향후 확장 예시
- 전체 페이지 크롤 대응 → 내부 링크를 재귀적으로 따라가 사이트 전체를 일괄 확인
- 병렬 처리(concurrent.futures) → 1000건의 URL을 고속 처리
- 정기 실행 + Slack 알림 → cron으로 자동 실행하고 에러 감지 시 Slack에 즉시 알림